Portkey
综合介绍
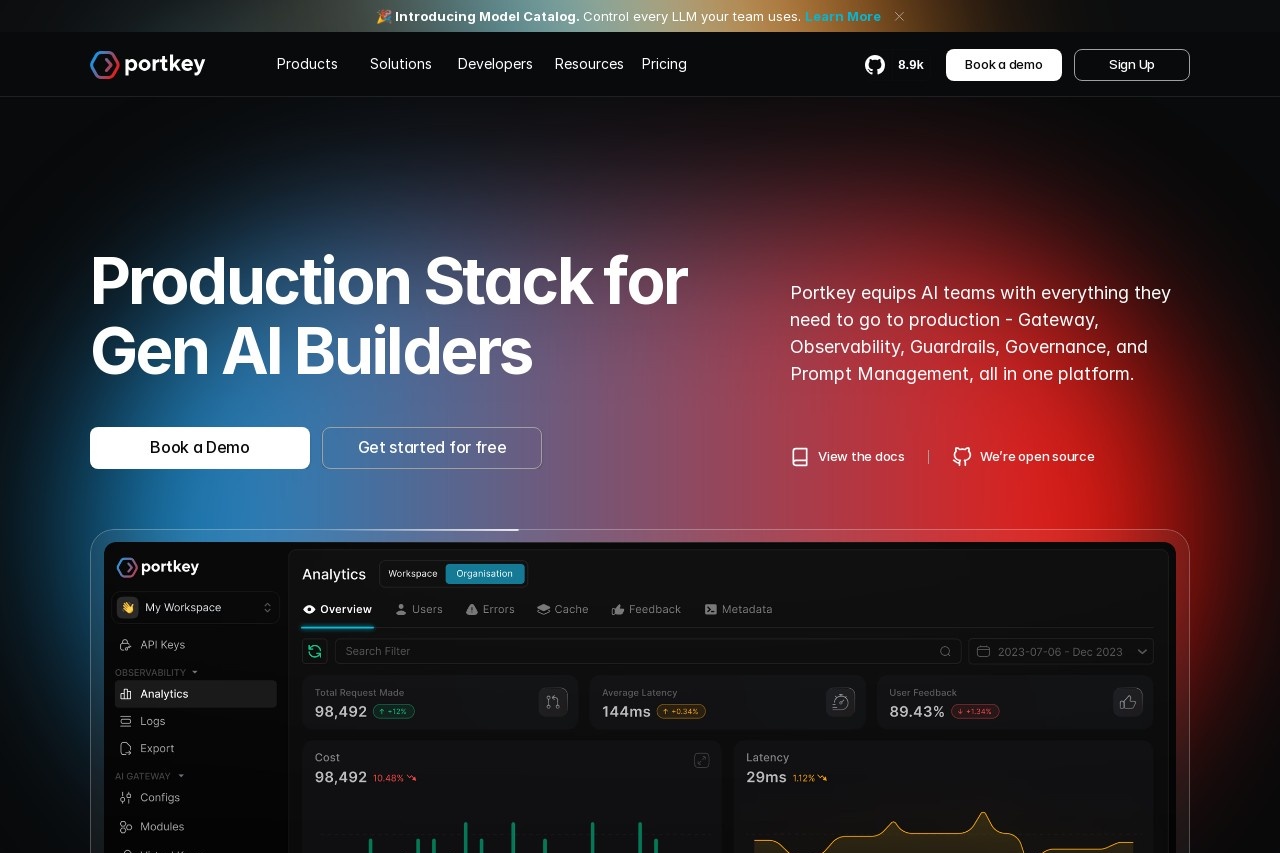
Portkey.ai是一个为人工智能(AI)开发者和团队设计的全功能平台,它提供了一个统一的AI网关,让开发者可以更简单、高效地构建、部署和管理基于大语言模型(LLM)的应用。 这个平台的核心是解决在生产环境中使用LLM时遇到的普遍问题,比如管理多个不同的模型、控制成本、保证应用的稳定可靠以及监控应用的性能。 通过Portkey,团队可以连接超过1600个来自OpenAI、Anthropic、Google等不同提供商的语言模型,而不需要为每个模型单独编写和维护代码。 它还提供了一系列工具,包括实时监控仪表盘、智能缓存、自动重试和备用模型切换、提示词版本管理和安全护栏等,所有这些功能都集成在一个控制面板中,旨在帮助开发者快速将AI功能投入生产并充满信心。
功能列表
- AI网关: 提供统一的API接口,可以连接和调用来自不同提供商(如OpenAI, Anthropic, Google Gemini, Llama2等)的超过1600个大语言模型,开发者无需修改大量代码即可在不同模型间切换。
- 可观测性 (Observability): 提供一个实时的监控仪表盘,可以追踪每一次AI请求的日志、延迟、token使用量和相关成本,帮助开发者及时发现和解决问题。
- 智能缓存 (Semantic Caching): 通过缓存相似的请求结果来减少对语言模型的重复调用,这不仅能大幅降低API费用,还能显著提高应用的响应速度。
- 可靠性功能:
- 自动重试 (Automatic Retries): 当API请求失败时,系统会自动重新尝试。
- 备用模型 (Fallbacks): 如果主模型出现故障或响应缓慢,系统可以自动切换到预设的备用模型,保证应用的持续可用。
- 负载均衡 (Load Balancing): 在多个模型或API密钥之间分配请求流量,以优化性能和成本。
- 提示词管理 (Prompt Management): 提供一个中央库来管理、测试、版本控制和部署提示词,方便团队协作和优化提示词效果。
- 成本管理与治理: 可以设置预算限制,实时监控各项AI服务的开销,并通过智能缓存和优化路由等方式帮助企业节省成本。
- 安全与合规: 提供虚拟API密钥、PII(个人身份信息)数据自动脱敏、基于角色的访问控制(RBAC)和详细的审计日志等功能,确保企业数据的安全,并符合GDPR、HIPAA等合规标准。
使用帮助
Portkey的设计目标是让开发者可以轻松上手,仅需少量代码改动即可集成到现有项目中,从而增强和管理你的AI应用。
第一步:注册并获取API密钥
首先,你需要访问Portkey.ai官方网站并注册一个账户。注册完成后,在你的账户仪表盘中,你会找到一个专属的Portkey API密钥。这个密钥是你的应用与Portkey网关通信的凭证。
第二步:集成Portkey AI网关
Portkey最核心的优势之一是它的“即插即用”能力。你不需要更换你正在使用的OpenAI或其他模型的SDK(软件开发工具包),只需要修改一处代码即可。
以在Python项目中使用OpenAI的SDK为例,你只需要将API请求的基础地址(base_url)指向Portkey的服务器地址即可。
原始代码示例 (直接调用OpenAI):
import openai
client = openai.OpenAI(
api_key="YOUR_OPENAI_API_KEY",
)
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hello world"}]
)
使用Portkey集成的代码示例:你只需要做出两处修改:
- 将
api_key替换为你的Portkey API密钥。 - 将
base_url设置为https://api.portkey.ai/v1。
import openai
client = openai.OpenAI(
api_key="YOUR_PORTKEY_API_KEY", # 使用Portkey的API密钥
base_url="https://api.portkey.ai/v1" # 指向Portkey网关
)
# 剩下的代码完全不用变
chat_completion = client.chat.completions.create(
model="gpt-4o-mini", # 你仍然可以指定使用哪个模型
messages=[{"role": "user", "content": "Hello world"}]
)
就这样,你的应用现在所有的AI请求都会通过Portkey的网关发送。这让你能够立即使用Portkey提供的各种强大功能。
如何操作主要功能
- 连接不同的LLM提供商在Portkey的仪表盘中,你可以安全地添加和管理来自不同提供商(如Anthropic, Google, Cohere等)的API密钥。添加后,当你在代码中发起请求时,只需要在
model参数中指定你想用的模型名称,Portkey会自动将请求路由到对应的提供商。例如,你想从OpenAI切换到Anthropic:# 请求Anthropic的Claude 3 Sonnet模型 chat_completion = client.chat.completions.create( model="claude-3-sonnet-20240229", messages=[{"role": "user", "content": "Hello world"}] )你不需要更换客户端或API密钥,Portkey会处理所有底层的兼容性问题。
- 设置可靠性策略(缓存、重试和备用模型)这些高级功能可以通过在请求头(Headers)中添加特定的配置来实现,无需更改你的业务逻辑代码。
- 启用缓存:添加
x-portkey-cache请求头。例如,"x-portkey-cache": "semantic"表示启用语义缓存,Portkey会理解请求的含义,如果一个语义上相似的请求已经存在,它会直接返回缓存的结果。 - 设置自动重试:添加
x-portkey-retry-count请求头,值为你希望重试的次数。例如,"x-portkey-retry-count": "2"表示在请求失败后最多重试2次。 - 配置备用模型:当主模型请求失败时,你可以让Portkey自动切换到另一个模型。
# 在请求的metadata中配置fallback client.with_options( extra_headers={ "x-portkey-fallbacks": '[{"model": "claude-3-haiku-20240307", "on_status_codes": [429, 500, 503]}]' } ).chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": "Tell me a story"}] )在上面的例子中,如果对
gpt-4o-mini的请求因为速率限制(429)或服务器错误(500, 503)而失败,Portkey会自动将同样的请求发送给claude-3-haiku-20240307模型。
- 启用缓存:添加
- 使用可观测性仪表盘集成Portkey后,你无需进行任何额外配置。直接登录到Portkey的网站仪表盘,你就可以看到所有通过网关的请求记录。
- 查看日志: 每一次请求的详细信息,包括请求内容、响应结果、token数量、耗时等都会被记录下来。
- 监控成本: 仪表盘会根据你的token使用量自动计算成本,并可以按模型、按时间或按自定义标签进行分组查看。
- 分析性能: 你可以轻松地看到不同模型的平均延迟、错误率等关键指标,帮助你做出优化决策。
- 管理提示词在Portkey的“Prompts”部分,你可以创建一个提示词库。
- 你可以创建新的提示词,并为它们编写不同的版本。
- 你可以在一个界面上测试同一个提示词在不同模型(如GPT-4o vs Claude 3)上的输出效果。
- 当你找到一个效果最好的提示词后,可以直接在应用中通过ID来调用它,而不需要在代码中硬编码长长的提示词文本。这使得更新和优化提示词变得非常简单。
通过以上步骤,你可以快速地将Portkey集成到你的AI应用中,并利用其丰富的功能来提升应用的稳定性、降低成本和简化管理。
应用场景
- 构建可靠的生产级AI应用当企业需要开发面向大量用户的AI应用(如智能客服、AI助手)时,应用的稳定性至关重要。开发者可以使用Portkey的自动重试和备用模型切换功能。 如果首选的GPT-4o模型因为流量过大或临时故障而响应失败,Portkey可以自动将请求切换到Anthropic的Claude 3模型,从而保证用户的请求总能得到处理,避免了服务中断。
- 控制和优化AI运营成本一家创业公司正在使用AI进行内容生成,但发现调用大模型的API费用增长很快。通过集成Portkey,他们可以启用语义缓存功能。 对于那些重复或主题相似的用户请求,系统可以直接返回缓存中的答案,而不是每次都去调用昂贵的语言模型。据Portkey用户反馈,仅此一项功能就能节省数千美元的开销。 同时,通过成本监控仪表盘,公司可以清楚地看到哪个功能或哪个模型花费最高,从而进行针对性优化。
- 快速实验和迭代不同的AI模型一个研发团队正在探索哪种语言模型最适合处理他们的特定任务,比如分析法律文件。传统方法需要为每个模型(Llama, Mistral, OpenAI模型等)编写不同的集成代码,非常耗时。使用Portkey的统一API,团队只需更改代码中的一个
model参数,就可以快速测试和比较不同模型的性能、准确率和延迟,极大地加快了研发和创新的速度。 - 团队协作与安全治理在一个拥有多个开发团队的大型企业中,管理谁在使用哪些AI模型以及如何保护敏感数据是一个挑战。Portkey提供了基于角色的访问控制(RBAC)和虚拟API密钥。 IT管理员可以为不同团队设置不同的权限和预算,并通过统一的审计日志追踪所有AI请求。当应用需要处理用户数据时,PII信息脱敏功能可以自动移除请求中的敏感信息,确保数据在发送给第三方AI模型前是安全的,满足了企业的合规性要求。
QA
- Portkey是什么?它能解决什么问题?Portkey是一个AI网关和控制平台,它像一个中间层一样位于你的应用程序和各种大语言模型(如OpenAI的GPT系列)之间。 它主要解决开发者在生产环境中构建AI应用时遇到的难题,包括:管理和切换多个不同AI模型的复杂性、控制不断增长的API成本、确保应用的高可靠性和稳定性,以及有效监控应用的性能和安全。
- Portkey支持哪些大语言模型?Portkey支持超过1600个来自主流提供商的模型,包括OpenAI、Google (Gemini)、Anthropic (Claude)、Mistral、Llama2、Anyscale等。 它的统一API接口让开发者可以使用同一套代码来调用这些不同的模型。
- 集成Portkey是否复杂?需要改动很多代码吗?集成非常简单,仅需大约2分钟和几行代码的改动。 你不需要更换现有的开发框架或SDK。通常只需要在你调用AI模型的代码处,将API密钥换成Portkey提供的密钥,并把请求的目标地址(base URL)指向Portkey的服务器即可。
- Portkey是如何帮助降低AI应用成本的?Portkey主要通过以下几种方式降低成本:
- 智能缓存:对于内容相似的重复请求,可以直接返回缓存结果,避免了对LLM的API调用,这是最有效的成本节省方式。
- 成本监控:仪表盘让你能清晰地看到每个模型、每个功能的具体花费,从而进行优化。
- 智能路由:你可以根据成本和性能,动态地将请求路由到性价比更高的模型上。
- 使用Portkey会增加我应用处理请求的延迟吗?不会。Portkey的AI网关经过了高度优化,其自身引入的延迟极低(官方称为0毫秒级别),对用户几乎没有感知。 相反,通过其智能缓存功能,Portkey反而可以大幅降低应用的平均响应延迟,因为它能迅速返回许多请求的结果而无需等待语言模型处理。