Agent Leaderboard
综合介绍
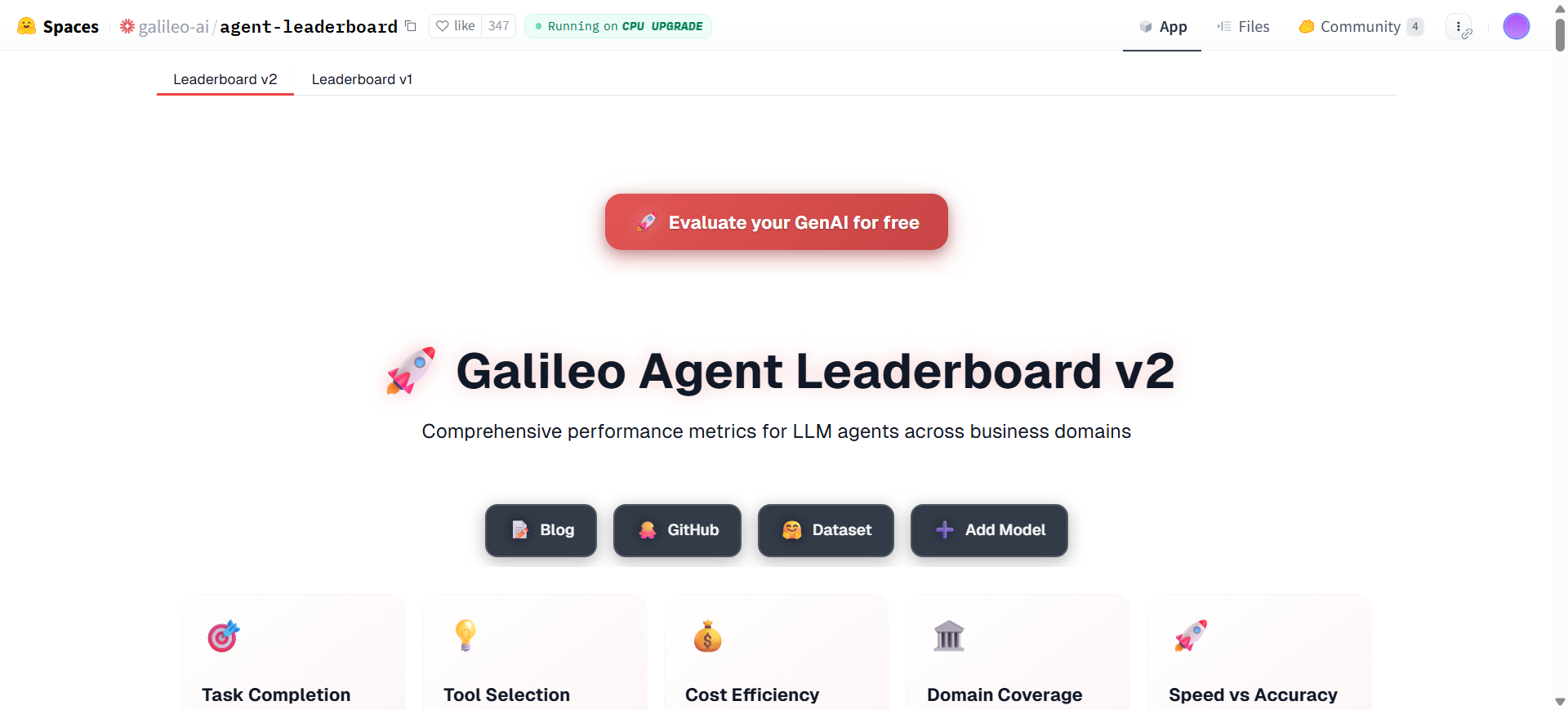
Agent Leaderboard 是由 Galileo AI 公司创建并托管在 Hugging Face 平台上的一个公开排行榜。 这个排行榜的核心目标是评估和比较不同的大语言模型(LLM)作为“AI智能体”在真实业务场景中的表现能力。 随着AI智能体(能够自主执行复杂任务的模型)变得越来越重要,企业在选择最适合自身需求的模型时面临挑战。 该排行榜通过一个统一的评估框架,测试包括OpenAI、Google、Mistral等公司在内的多个主流模型,并根据其性能进行排名。 评估的重点在于模型使用工具和函数调用的准确性与效率,最终生成一个名为“工具选择质量”(Tool Selection Quality, TSQ)的核心分数。 用户可以通过这个排行榜直观地看到各个模型的排名、分数、开发商、成本以及是否开源等关键信息,从而为技术选型提供数据支持。
功能列表
- 查看综合排名:排行榜会根据核心指标“工具选择质量”(TSQ)对所有参与测试的AI智能体进行综合排名。
- 比较模型性能:用户可以直观地比较来自不同供应商(如Google, OpenAI, Meta等)的多种模型。
- 获取关键指标:除了总分,排行榜还提供每个模型在具体基准测试(如BFCL, ToolACE)上的详细分数。
- 了解模型信息:提供每个模型的基础信息,包括其开发商、运营成本估算以及该模型是开源还是闭源。
- 定期更新:排行榜会定期(例如每月)更新,以反映AI领域快速发展的最新模型和技术能力。
- 评估真实世界表现:排行榜的测试基准涵盖了零售、航空、数学、娱乐等多种真实世界的应用领域。
- API访问:排行榜提供通过API调用的方式,方便开发者将排行榜数据集成到自己的应用或工作流中。
使用帮助
Agent Leaderboard 是一个为开发者、研究人员和企业决策者设计的在线工具,旨在帮助他们清晰地了解并选择最适合自己需求的AI智能体。整个界面的设计非常直观,无需安装任何软件,通过浏览器即可直接访问和使用。
界面核心与布局
访问该网站后,你会看到一个主表格,这就是排行榜的核心。这个表格清晰地列出了当前市场上主流的AI智能体(大语言模型)及其性能数据。表格通常包含以下几列:
Rank(排名):根据模型的综合分数进行排序,数字越小代表排名越高。Model(模型):被评估的AI智能体模型的具体名称,例如OpenAI的gpt-4o-2024-11-20或Google的gemini-2.0-flash-001。 点击模型名称通常可以跳转到该模型的官方页面或Hugging Face页面。TSQ(工具选择质量):这是Galileo公司提出的核心评估指标,分数范围通常在0到1之间。 这个分数衡量了模型在模拟任务中正确选择和使用“工具”(如API调用、函数调用)的能力。分数越接近1,代表模型在执行具体任务时的准确性和效率越高。例如,得分超过0.9的模型会被评为“精英级”(Elite Tier Performance)。Vendor(供应商):开发该模型的公司或组织,如OpenAI, Google, Mistral等。Cost(成本):模型的使用成本估算,通常以每百万个输入和输出token(文本单位)的价格来表示。 这对于需要考虑预算的用户来说是一个非常重要的参考指标。Open Source(是否开源):标明该模型是开源项目还是闭源的私有模型。开源模型允许用户自由下载、修改和部署,而闭源模型通常只能通过API付费使用。
如何操作和解读
上手使用这个排行榜非常简单,主要操作集中在浏览、排序和信息筛选上:
- 浏览和比较:你可以上下滚动页面,查看所有被收录的模型。默认情况下,模型是按照
TSQ分数从高到低排列的。你可以快速看到当前排名前几位的模型是哪些,它们分别来自哪家公司,以及它们的性能和成本差异。例如,你可能会发现Google的Gemini模型和OpenAI的GPT-4o模型长期占据榜首位置,但它们的成本有所不同。 - 理解评估基准:排行榜的分数并非单一来源,而是综合了多个专业的基准测试集。这些测试集模拟了AI智能体在真实世界中可能遇到的各种挑战,例如:
BFCL: 专注于学术领域,如数学计算和教育问答。ToolACE: 侧重于模型与多达390个不同API进行交互的能力。τ-bench: 主要测试在零售和航空等商业场景下的任务处理能力。虽然你不需要深入了解每一个基准的细节,但知道它们的存在有助于你理解排行榜分数的全面性和可靠性。
- 筛选和排序(如果支持):一些排行榜界面允许用户点击列标题进行排序。例如,你可以点击
Cost列,将模型按成本从低到高排列,从而找到性价比最高的模型。或者,你可以筛选只看Open Source的模型,如果你想寻找一个可以私有化部署的解决方案。 - 获取最新信息:AI技术迭代非常快,新的模型层出-不穷。该排行榜会定期更新,所以你可以将它作为一个持续关注行业动态的窗口。 每次访问时,都可能看到新模型的加入或者现有模型排名的变化。
通过上述方式,即便是非技术背景的用户也能快速上手,并根据自己的具体需求(如追求最高性能、最佳性价比或开源方案),在众多模型中做出明智的选择。
应用场景
- 企业技术选型企业在开发需要调用外部API或执行复杂指令的智能应用时,可以使用该排行榜来评估不同大语言模型的工具调用能力。通过比较
TSQ分数和Cost,企业可以在性能和预算之间找到最佳平衡点,选择最适合其业务场景的AI模型。 - AI开发者选择基础模型AI应用的开发者需要为他们的智能体挑选一个可靠的基础模型。该排行榜提供了一个直观的性能对比平台,帮助开发者快速判断哪个模型在处理函数调用和多工具协作方面更稳定、更准确,从而减少开发过程中的试错成本。
- 研究人员跟踪前沿进展对于从事人工智能研究的学者和学生来说,这个排行榜是观察和分析AI智能体技术发展的绝佳窗口。他们可以通过榜单排名的变化,了解最新、最强大的模型是哪些,以及当前AI在自动化任务执行方面所达到的技术水平和局限性。
- 产品经理规划产品功能产品经理在设计包含AI功能的产品时,需要了解当前AI能力的边界。通过查阅排行榜,产品经理可以得知市场上顶尖模型的性能水平,从而更切实际地规划产品路线图,避免设计出当前技术难以实现的功能。
QA
- 这个排行榜评估的是AI的什么能力?这个排行榜主要评估AI模型作为“智能体”(Agent)时,使用工具(Tool)的能力。具体来说,就是衡量模型在面对一个任务时,能否准确地理解指令,并正确地选择一个或多个API(工具)来完成任务,以及传递的参数是否准确。这项能力对于AI完成真实世界的复杂任务至关重要。
- TSQ分数是什么意思,为什么它很重要?TSQ是“Tool Selection Quality”(工具选择质量)的缩写,是Galileo公司设计的一个核心评估指标。 它综合了模型在多个基准测试中的表现,全面反映了模型在工具选择和参数使用上的准确性。一个高的TSQ分数意味着这个AI智能体在执行任务时更可靠、更高效,犯错的几率更低。
- 排行榜多久更新一次?排行榜会定期更新,通常是每月一次。 这样做是为了及时反映AI领域快速发布的新模型和技术更新,确保用户看到的信息具有时效性。
- 为什么有些知名的模型没有出现在排行榜上?排行榜的收录标准之一是模型需要具备足够稳定和强大的函数调用(Function Calling)功能。某些模型如果在这方面支持有限或表现不佳,可能会被暂时排除在排名之外,直到其能力达到评估要求。