AIGC软件库
首页
AI助手
绘画
视频
音频
学习
效率
商业
营销
生活娱乐
开发者工具
专业工具
免费模型API
基础模型
副业项目
提交AI工具
首页
KV Cache
KV Cache
深入解析KV Cache技术原理及其在Transformer大模型中的优化作用,帮助开发者显著提升推理性能并降低计算成本。
直达
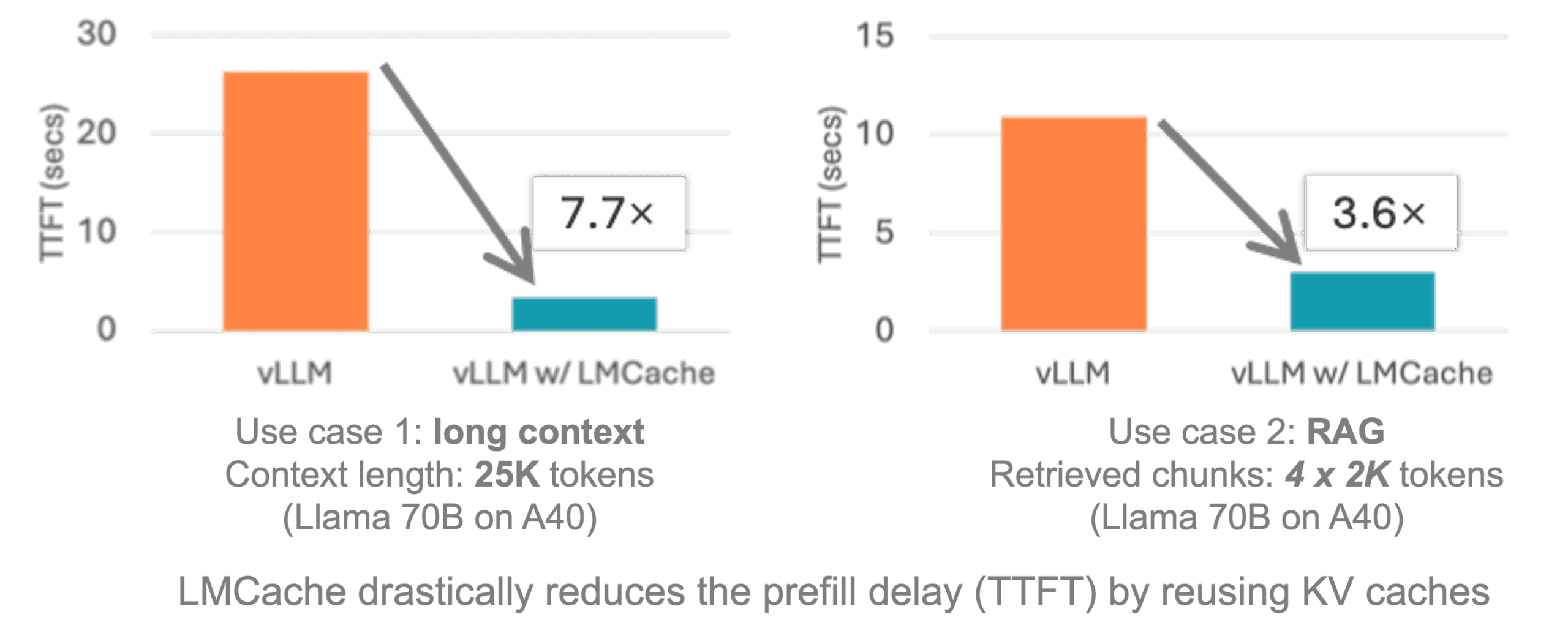
LMCache
加速大语言模型推理的KV缓存层
KV Cache
LLM
LMCache
返回顶部